本文共 2867 字,大约阅读时间需要 9 分钟。
报表开发过程中经常要在报表中完成数据关联计算,有时为了降低报表制作复杂度,会将关联关系放到可视的报表模板中完成;而有时则必须在报表中完成关联,如多数据源、异构数据源的情况。在报表中做关联往往导致报表效率不高,计算过慢,从而引发性能问题。为此,润乾报表提供了高性能数据关联方式(需要结合集算器实现),可以显著提升报表的计算效率。这里就通过一个常见的多源关联分片报表实例来说明润乾报表的实现过程:
报表说明
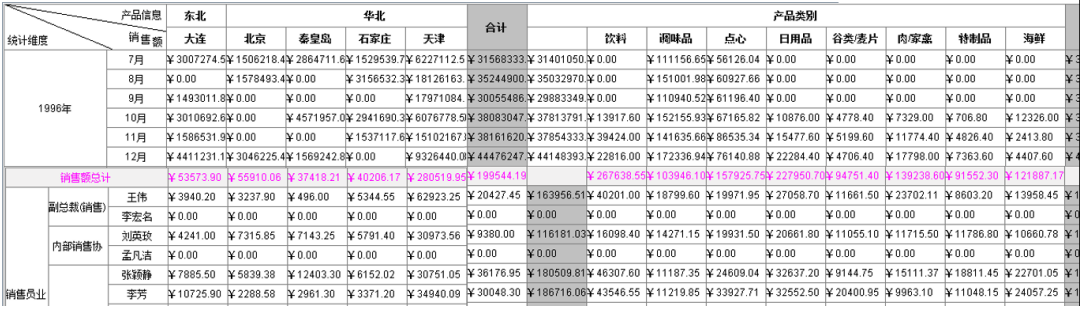
根据销售情况等信息按照时间、地区、销售人员、产品等维度汇总销售额,报表样式如下:
以下为实现过程。
编写计算脚本
首先使用集算器编写脚本,完成数据关联,并为报表返回关联后的结果集。
| A | |
|---|---|
| 1 | =connect(“demo”) |
| 2 | =A1.query(“SELECT 客户. 地区, 客户. 城市, 订单明细. 数量, 订单明细. 折扣, 订单明细. 单价, 订单. 雇员 ID, 订单. 订购日期, 订单明细. 产品 ID FROM 订单明细, 订单, 客户 WHERE 客户. 客户 ID = 订单. 客户 ID AND 订单. 订单 ID = 订单明细. 订单 ID and 订单. 订购日期 is not null”) |
| 3 | =A1.query(“SELECT 类别. 类别 ID, 类别. 类别名称 FROM 类别”) |
| 4 | =A1.query(“SELECT* from 雇员”) |
| 5 | =A1.query(“SELECT 产品. 类别 ID, 产品. 产品 ID FROM 产品”) |
| 6 | >A5.switch(类别 ID,A3: 类别 ID) |
| 7 | >A2.switch(雇员 ID,A4: 雇员 ID) |
| 8 | >A2.switch(产品 ID,A5: 产品 ID) |
| 9 | =A2.new(year( 订购日期): 年,month(订购日期): 月, 地区, 城市, 单价 * 数量: 金额, 雇员 ID. 职务: 职务, 雇员 ID. 雇员 ID: 雇员 ID, 雇员 ID. 姓氏 + 雇员 ID. 名字: 姓名, 产品 ID. 类别 ID. 类别 ID: 类别 ID, 产品 ID. 类别 ID. 类别名称: 类别名称 ) |
| 10 | return A9 |
A1:连接数据源;
A2-A5:执行 sql,分别取订单、产品等库表数据;
A6-A8:使用 switch 将多表数据完成关联,关联结果存入 A2 格中;
A9:根据已关联结果创建新序表,结果集通过 A10 返回报表。
编制报表
在润乾报表设计器中新建报表模板后,数据集选择“集算器”,在数据集编辑窗口指定上述编辑好的 dfx 文件,完成数据集创建。
编辑报表模板表达式:
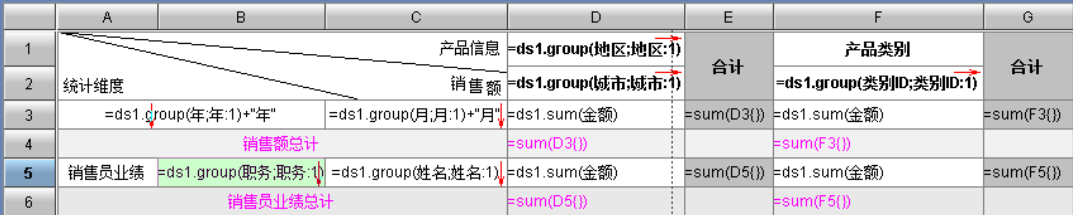
不同于报表模板中的低效关联,集算报表是事先在集算脚本中完成关联,报表模板只需从结果集取数,从而获得更高的性能。
为了对照,我们再按照传统的报表中实现关联的方式做一下:
报表中实现关联
数据集
ds1: SELECT 客户. 地区, 客户. 城市, 订单明细. 数量, 订单明细. 折扣, 订单明细. 单价, 订单. 雇员 ID, 订单. 订购日期, 订单明细. 产品 ID FROM 订单明细, 订单, 客户 WHERE 客户. 客户 ID = 订单. 客户 ID AND 订单. 订单 ID = 订单明细. 订单 ID and 订单. 订购日期 is not null
ds2: SELECT 类别. 类别 ID, 类别. 类别名称 FROM 类别
ds3: SELECT * from 雇员
ds4: SELECT 产品. 类别 ID, 产品. 产品 ID FROM 产品
报表模板

对比效果
本例的源表数据为 40 多万条,基于同样的取数 sql,两种关联方式的运行时间如下表所示:
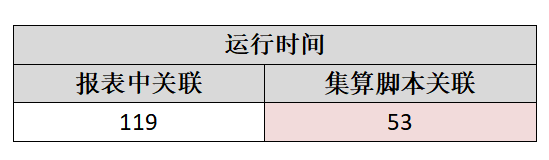
可以看到,润乾报表在处理关联计算类报表时有明显的优势。这是因为在报表中实现关联只能使用遍历算法,针对单条主记录去寻找关联的子记录,因此效率不高;而集算器采用了更高效的 hash 关联方案,事先将所有子记录按对应码 hash 到主记录上(代码中的 switch 函数就利用了 hash 关联技术),因而能获得一倍以上的性能提升(如果只算关联能快出 5-10 倍)。
此外,集算器也非常适合处理异构数据源的数据关联,如常见的跨库计算、文件和数据库混合计算等情况。
下附运行日志和测试机配置。
【附 1】运行日志
报表中关联
[2018-09-15 11:32:59] : [INFO] - 开始运算报表,首先取数……
[2018-09-15 11:32:59] : [DEBUG] - 下面开始打出 sql
[2018-09-15 11:32:59] : [DEBUG] - ds1=SELECT 客户. 地区, 客户. 城市, 订单明细. 数量, 订单明细. 折扣, 订单明细. 单价, 订单. 雇员 ID, 订单. 订购日期, 订单明细. 产品 ID FROM 订单明细, 订单, 客户 WHERE 客户. 客户 ID = 订单. 客户 ID AND 订单. 订单 ID = 订单明细. 订单 ID and 订单. 订购日期 is not null
[2018-09-15 11:33:35] : [DEBUG] - 下面开始打出 sql
[2018-09-15 11:33:35] : [DEBUG] - ds2=SELECT 类别. 类别 ID, 类别. 类别名称 FROM 类别
[2018-09-15 11:33:35] : [DEBUG] - 下面开始打出 sql
[2018-09-15 11:33:35] : [DEBUG] - ds3=SELECT * from 雇员
[2018-09-15 11:33:35] : [DEBUG] - 下面开始打出 sql
[2018-09-15 11:33:35] : [DEBUG] - ds4=SELECT 产品. 类别 ID, 产品. 产品 ID FROM 产品
[2018-09-15 11:33:35] : [INFO] - 取数结束, 开始运算
[2018-09-15 11:34:58] : [INFO] - 计算结束:
dfx 中关联
[2018-09-15 11:56:33] : [INFO] - 开始运算报表,首先取数……
[2018-09-15 11:57:11] : [INFO] - 取数结束, 开始运算
[2018-09-15 11:57:26] : [INFO] - 计算结束:
【附 2】测试机配置
测试机型:Dell Inspiron 3420
CPU:Intel Core i5-3210M @2.50GHz *4
RAM:4G
HDD:西数 WDC(500G 5400 转 / 分)
操作系统:Win7(X64) SP1
JDK:1.6
数据库:oracle11g R2
润乾报表版本:2018
详情链接:?r=gxy
转载地址:http://gkabl.baihongyu.com/